-
RNNetc/데이터분석.머신런닝.딥러닝 2022. 2. 2. 14:52
RNN
Recurrent Neural Networks(RNN), long Short-Term Memory models(LSTM)
Rnn:
1.시퀀스의 길이에 관계 없이 인풋과 아우풋을 받아 들일 수 있는 네트워크 구조
2. 모든 시점의 state에서 파라미터(Why )를 동일하게 적용

초록 상자가 hidden. state Temporal-Difference Learning,,?

초록색은 순전파 , 붉은색은 역전파 RNN 도 vanishing gradient problem. solution -> LSTM. or Gru

cell-state struct https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
RNN과 LSTM을 이해해보자! · ratsgo's blog
이번 포스팅에서는 Recurrent Neural Networks(RNN)과 RNN의 일종인 Long Short-Term Memory models(LSTM)에 대해 알아보도록 하겠습니다. 우선 두 알고리즘의 개요를 간략히 언급한 뒤 foward, backward compute pass를 천천
ratsgo.github.io
예제:

hidden_size = output size
sequence_length =Rnn 의 갯수 , 시계열 입력 데이터의 입력
batch_size = 'hello', 'eolll', 'lleel' : 배치 사이즈 3 줄입력 행의 수
# outputs: ht 값 , states :영향을줄 states값 옆으로 나온거
# One cell RNN input_dim (4) -> output_dim (2). sequence: 5, batch 3 x_data = np.array([[h, e, l, l, o], [e, o, l, l, l], [l, l, e, e, l]], dtype=np.float32) hidden_size = 2 rnn = layers.SimpleRNN(units=2, return_sequences=True, return_state=True) outputs, states = rnn(x_data) print('x_data: {}, shape: {} \n'.format(x_data, x_data.shape)) print('outputs: {}, shape: {} \n'.format(outputs, outputs.shape)) print('states: {}, shape: {}'.format(states, states.shape))단어 ok -> 문장 ? 감정 ?
Word sentiment classification problem. ( many to one)
["This movie is good"]. -> Tokenization->RNN -> Classification -> "good".-> Positive.


# creating simple rnn for "many to one" classification input_dim = len(char2idx) output_dim = len(char2idx) one_hot = np.eye(len(char2idx)) hidden_size = 10 num_classes = 2 model = Sequential() model.add(layers.Embedding(input_dim=input_dim, output_dim=output_dim, trainable=False, mask_zero=True, input_length=max_sequence, embeddings_initializer=keras.initializers.Constant(one_hot))) #mask_zero=true , 0값 패딩 부분 연산시 건너 뜀 #trainable = false : One hot vector train skip model.add(layers.SimpleRNN(units=hidden_size)) model.add(layers.Dense(units=num_classes)) model.summary()many to one stacking

Stacked RNN sematic infromataion-> 의미의, 의미 추론은 output 근처
syntactic -> 구문의 : 입려된 문장의 문법적완성도를 높이는것은 input layer의 근처 : cnn 처럼 abstract
# creating stacked rnn for "many to one" classification with dropout num_classes = 2 hidden_dims = [10,10] input_dim = len(char2idx) output_dim = len(char2idx) one_hot = np.eye(len(char2idx)) model = Sequential() model.add(layers.Embedding(input_dim=input_dim, output_dim=output_dim, trainable=False, mask_zero=True, input_length=max_sequence, embeddings_initializer=keras.initializers.Constant(one_hot))) #layer1 model.add(layers.SimpleRNN(units=hidden_dims[0], return_sequences=True)) # return_sequences : [data_dim,input_sequence,output_dim] # 다음 Rnn 의 데이터를 받기좋게만듬 model.add(layers.TimeDistributed(layers.Dropout(rate = .2))) # stacked Rnn model capacity >> shallow one so could be overfitting #https://keras.io/api/layers/recurrent_layers/time_distributed/ #layer2 model.add(layers.SimpleRNN(units=hidden_dims[1])) model.add(layers.Dropout(rate = .2)) model.add(layers.Dense(units=num_classes))동사 명사 ? 품사 파악
POS- tagger problem (Part Of Speech Tagging. )
Many to Many (bidirectional)
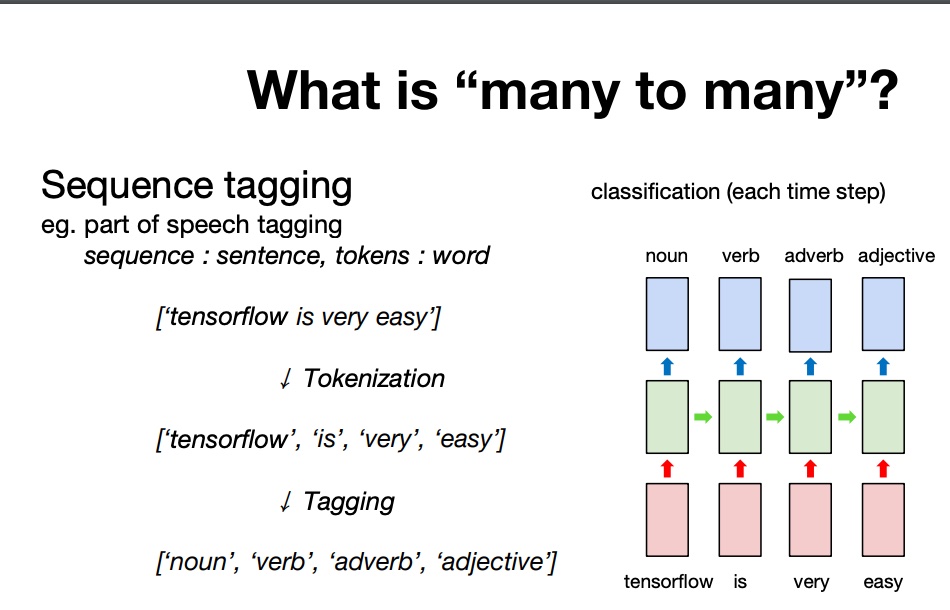

위와 같은 many to many는 hidden state 간 정보의 불균형이 존재한다.

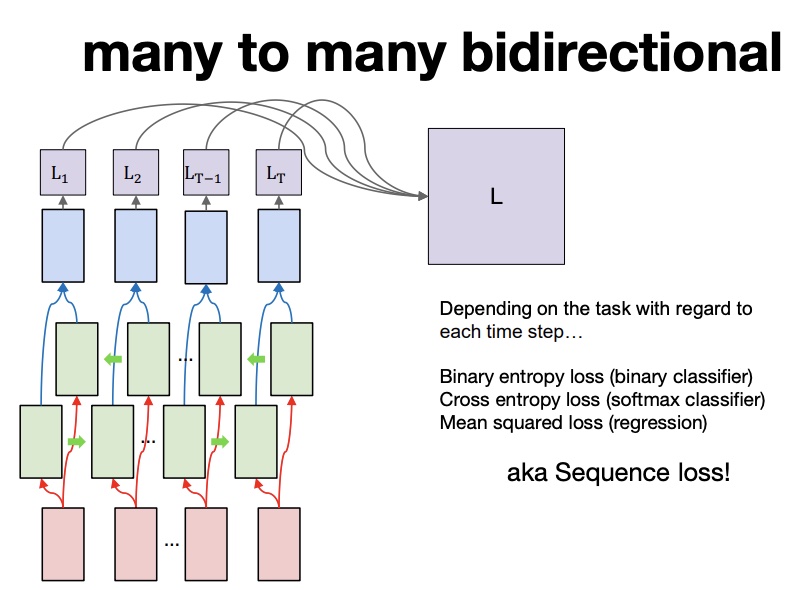
투 포인트 소팅 같은 느낌? 위와 같은 모델을 사용할 경우 hidden state 의 정보를 줄인다.

여기서 구한 weoght 와 bias 는 모든 토큰에 적용된다 seq to seq(attention) : example of using chat bot , 번역


encoder : 입력값 유저의 말 처리
decoder: 출력값을 처리 하는 부분 outut 은 단어의 형태로 나온다.

1. decoder :start token end token , 다음 step의 입력으로 들어감
2.sequence 4 로 설정 , padding
problem: 중간의 벡터가 한개이면 입력 된 정보를 모두 담기 어렵다 , 문장이 길어지면 성능이 감소한다.
solution : Attention. -> 문장에서 중요한것에만 집중


attention weights 를 모든 state마다 준다.